
Summary
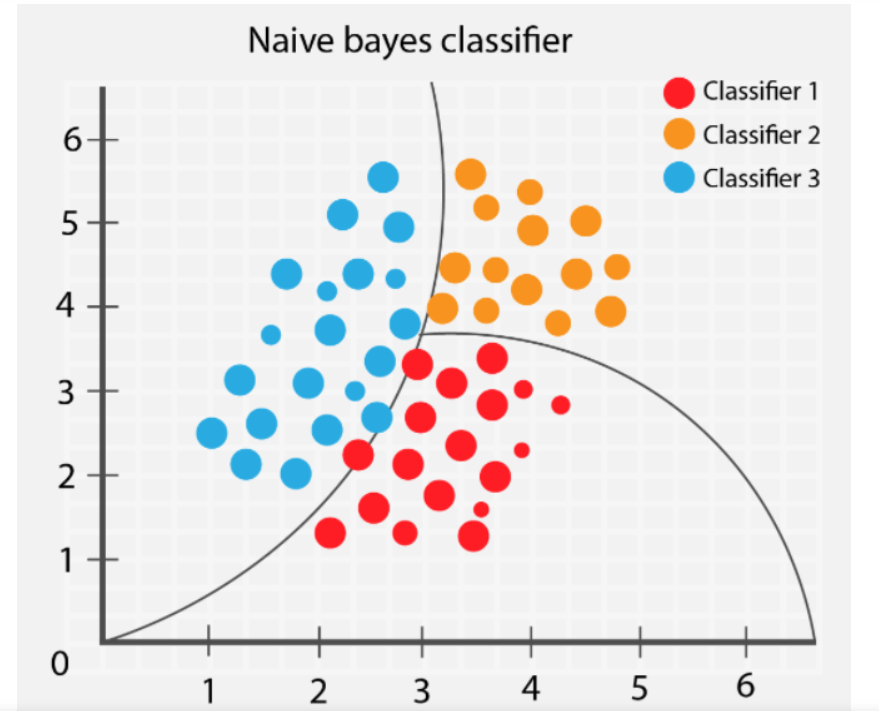
This is an implementation for a simple naive bayes algorithm, a probabilistic classification algorithm based on Bayes’ theorem, which assumes that the features used to describe an observation are conditionally independent, given the class label. Despite its “naive” assumption of independence, it often performs well in practice, especially for text classification tasks. It is then applied to a dataset that deals with adults profiles and their income.
Details
This implementation computes a score for each value on each variable and with respect their income. The variables covered in the dataset are:
- age
- workclass
- education
- marital status
- occupation
- relationship
- race
- sex
- hours per week
- native country
Age and hours per week are converted into categorical variables by placing them into bins (quintiles).
Formula
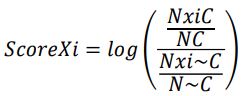
C: Our main class, in this case “income”.
NxiC: is the number of elements of the variable x with value i, which belong to the class.
NC: is the total number of elements in the class.
Nxi~C: is the number of elements of the variable x with value i, which are not in the class.
N~C: is the total number of elements in the non-class.
Observations
Because the dataset is overpopulated by white USA males, people from other countries in a good situation may automatically be “well-classified”.